I was originally going to title this article “The Art & Science of Code Documentation”, but the more I thought about it, the more I realised there isn’t a lot of science behind it. It really does become a fairly subjective thing. Some people comment and document more than others, some files 100’s of lines long don’t need documentation, some that are under 100 lines desperately do.
But there is an art to it, and there are a set of good, strong guidelines that if followed, will ensure that your code remains readable for yourself in 2 years time, or to the next person to try and decipher just what the hell you were doing.
Let’s go over them.
Commenting Code vs Documenting Code
This is probably the biggest thing to remember: there’s a difference between commenting code and documenting code. Which one you want to do at what point is not a subjective thing, these two words have very specific meanings.
Don’t get caught up thinking that all of your comments counts towards documenting code. And conversely, don’t think that documenting your code is the same as commenting it. Again, they are two separate things. Let’s talk about each and set some definitions. Then we’ll go over everything in a bit more detail.
For the sake of providing some context, I’ll be providing examples in C/C++, but many language follow the same comment delimiters so it should be very transferable. Don’t get caught up in the language of choice, just worry about the comments and documentation.
What is Commenting Code?
Commenting code is when you add some helpful information within a function that explains what the next piece of code is going to do. Here’s an example from my own code used to generate a limited colour palette for the median-cut algorithm:
std::vector<P> median_cut_generate_palette(const std::vector<P>& source, const std::uint_fast32_t numColors)
{
typedef std::vector<P> Box;
typedef std::pair<std::uint8_t,Box> RangeBox;
std::vector<RangeBox> boxes;
Box init = source;
boxes.push_back(RangeBox(0,init));
while(boxes.size() < numColors)
{
// for each box, sort the boxes entries according to the colour it has the most range in
for(RangeBox& boxData : boxes)
{
std::uint8_t redRange;
std::uint8_t greenRange;
std::uint8_t blueRange;
std::uint8_t alphaRange;
if(std::get<0>(boxData) == 0)
{
determine_primary_color_and_sort_box(std::get<1>(boxData),redRange,greenRange,blueRange,alphaRange);
if(redRange >= greenRange && redRange >= blueRange && redRange >= alphaRange)
std::get<0>(boxData) = redRange;
else if(greenRange >= redRange && greenRange >= blueRange && greenRange >= alphaRange)
std::get<0>(boxData) = greenRange;
else if(blueRange >= redRange && blueRange >= greenRange && blueRange >= alphaRange)
std::get<0>(boxData) = blueRange;
else
std::get<0>(boxData) = alphaRange;
}
}
std::sort(boxes.begin(),boxes.end(),[](const RangeBox& a, const RangeBox& b)
{
return std::get<0>(a) < std::get<0>(b);
});
std::vector<RangeBox>::iterator itr = std::prev(boxes.end());
Box biggestBox = std::get<1>(*itr);
boxes.erase(itr);
// the box is sorted already, so split at median
Box splitA(biggestBox.begin(), biggestBox.begin() + biggestBox.size() / 2);
Box splitB(biggestBox.begin() + biggestBox.size() / 2, biggestBox.end());
boxes.push_back(RangeBox(0,splitA));
boxes.push_back(RangeBox(0,splitB));
}
// each box in boxes can be averaged to determine the colour
std::vector<P> palette;
for(const RangeBox& boxData : boxes)
{
Box box = std::get<1>(boxData);
std::uint_fast32_t redAccum = 0;
std::uint_fast32_t greenAccum = 0;
std::uint_fast32_t blueAccum = 0;
std::uint_fast32_t alphaAccum = 0;
std::for_each(box.begin(),box.end(),[&](const P& p)
{
redAccum += p.r;
greenAccum += p.g;
blueAccum += p.b;
alphaAccum += p.a;
});
redAccum /= static_cast<std::uint_fast32_t>(box.size());
greenAccum /= static_cast<std::uint_fast32_t>(box.size());
blueAccum /= static_cast<std::uint_fast32_t>(box.size());
alphaAccum /= static_cast<std::uint_fast32_t>(box.size());
palette.push_back(
{
static_cast<std::uint8_t>(std::min(blueAccum,255u)),
static_cast<std::uint8_t>(std::min(greenAccum,255u)),
static_cast<std::uint8_t>(std::min(redAccum,255u)),
static_cast<std::uint8_t>(std::min(alphaAccum,255u))
});
}
return palette;
}Code language: C++ (cpp)Notice that the comments are short, single line affairs that come before the section of code in question.
Comments are short, explanatory sentences used to give the reader a starting point from which they can understand the proceeding section of code.
What is Documenting Code?
On the other side, documenting the code is when you provide in-depth explanation for the purpose of a piece of code, how to interfaces with other constructs in the codebase, and finally, the interface of the code. Here’s another example, again, from my own code:
/** \brief Finds the optimal path across nodes if a path exists
*
* Uses the supplied Heuristic function to make a guess at the cost of moving from one node to another node.
*
* Uses the supplied GetNeighbors function to return a list of neighboring nodes.
*
* Uses the supplied IsNodeAvailable function to determine, while processing, if it can use the node. This
* is used so that a single map can be provided but it may be dynamically altered slightly between paths being
* found.
*
* Uses the supplied TraverseCost function to determine the cost of moving between two nodes. This will only
* ever be provided two nodes that are neighbors. You could safely provide a very large value for nodes which
* are not neighbors or nodes which you want the path to avoid (perhaps there was recent enemy activity there)
*
* \tparam UnitType The data type used to determine costs to move between nodes
* \tparam NodeType The data type used for each node, typically a struct which contains the data needed for the
* functions, or a tag that those functions can use to look-up the needed values (maybe just an x,y coordinate).
* \tparam Heuristic Of the form `const UnitType&(const NodeType& a, const NodeType& b)`
* \tparam GetNeighbors Of the form `std::deque<NoodeType>&(const NodeType& n)`
* \tparam IsNodeAvailable Of the form `bool(const NodeType& n)`
* \tparam TraverseCost Of the form `void(const NodeType& a, const NodeType& b, UnitType&)`
* \param start The starting node
* \param goal The node we want to find a path to
* \param path Where to put the resulting path if found
* \return `true` if a path could be found or otherwise `false`
*
*/
template<
typename UnitType,
typename NodeType,
class HeuristicFunc,
class NeighbourFunc,
class IsAvailableFunc,
class TraverseCostFunc>
bool a_star(const NodeType& start, const NodeType& goal, std::deque<NodeType>& path,
HeuristicFunc heuristicFunc,
NeighbourFunc neighbourFunc,
IsAvailableFunc isAvailableFunc,
TraverseCostFunc traverCostFunc);Code language: C++ (cpp)Note that there’s a full explanation on what this function is, what it does, and the parameters needed. You might also notice that there’s some weird stuff like \tparam etc, I’ll get to explaining that stuff soon.
Documenting is done to provide full information on a construct of code, what it does, why it does, how it does; and what the user needs to utilize it.
Why should I comment my code?
Often times we game developers are asked to implement a lot of different things. Artificial intelligence, rendering, sound, you know the deal. An inevitable side-effect of this ask is that we will forget things. And you know how you develop, you need to implement pathfinding, so what do you do? You research different path-finding methods, implement the one you think will work the best, then you test and make sure everything is working.
And then what do you do?
You forget it. It’s gone. Those valuable brain cells are now being used for the rendering code that you need to do next. After that it’s been replaced for the planning A.I. that needs doing. Every step of the way, you’re learning something, implementing, and then forgetting.
Of course, with experience, this stuff comes back into your brain faster, and with experience you get better at switching etc. And if there’s something that experience has taught me, it’s that commenting my code will help me remember everything I forgot a lot quicker.
This is important because we all know what happens after we implement the pathfinding, rendering, and planning A.I. don’t we? Yeah, there’s bugs. The pathfinding gets stuck on something it shouldn’t (turns out the rendering code isn’t rendering the rock it’s stuck on), the planning A.I. can’t seem to use the pathfinding correctly and so it never tries to gather more resources on one corner of the map.
And because, as you can see above, this code is interlinked, it’s hard to know exactly where the bug is. So we’ve got to go through each of these sections of code, one by one, until we uncover the problem. And each of these sections is a completely different subject domain. Now we have the daunting task of relearning each facet of the code as we go along.
That’s where those comments come in:
- Reminders on how the algorithm is supposed to work
- Helpful explanations on why a particular mangey looking piece of template meta-programming was done
- URLs to web-pages that explain the technique being used in more detail
That’s why you comment your code.
Why should I document my code?
Documentation isn’t just for teams! I do it, and I am a forever alone solo hobby game developer. I do it because I need to. I do it because 40,000 lines of code become too much for me. All the comments in the world don’t help.
You know why? Because I haven’t got the time.
I have not got the time to go through a function and read the code to remember what it does. Even those helpful comments explaining the algorithm aren’t enough. Or maybe they’re too much? I don’t care, at this point anyway, how the algorithm works, I just need to remember how to use the function.
This is why you document your code if you’re on your own.
In my day job I’m in a team. And we document our code for the exact same reason. It doesn’t matter who wrote the code. Remember? You already forgot the finer details when you moved onto the next thing. Not only did you forget how the algorithm works, you forgot the format of the data you’re supposed to pass in. Documented code provides that detail without needing to track down the source file, the line of code, and decipher all the function calls.
Documentation doesn’t help find bugs so much. It helps re-use and utilize your existing code. It helps make it useable for others, and that includes your future self.
When is a good time to comment code?
This is where it’s more of an art than a science. There is such a thing as too many comments. Code, first and foremost, should be readable. This often means that you don’t need lines and lines of explanatory comments.
// add the two numbers together
int c = a + b;Code language: JavaScript (javascript)Oh good lord why? Who is this going to help? We’re not writing a beginners guide to programming, we don’t need to explain operators.
Good code, well-written code, is self-commenting (notice that I did not say self-documenting). Code should be clear, concise, and readable. This means that if you can remove a comment by breaking code up into named functions that explain what they do then do it! You don’t need to add comments around an operator in the same way you don’t need to add a comment around a function call like:
int c = add_two_numbers_together(a, b);Make your code readable. It might take a little bit of extra time, and that’s fine. It might not be your style, and that’s fine too. Use your refactor day to do it in (read more in Getting Games Done in 2020). You’ll thank you past self later.
So when do you comment code? When you have no other choice. You can’t explain it any better, because it’s just wtf code. If you’re in a team, consider the skill levels of the team, some need more help understanding code than others. That means you’re senior, so take some responsibility and make their learning curve easier by leaving them useful, concise comments to help them along. That’s less people coming up to you with questions and killing your flow.
Here’s a great example of a comment (not my code, I’m not that clever):
float Q_rsqrt( float number )
{
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fuck?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}Code language: C++ (cpp)This is the infamous Fast Inverse Square Root made famous by John Carmack in the Quake 3 source-code. You simply need to leave comments to explain what this code is doing.
Tools for code documentation?
Nothing will help you to comment your code. You just need to do it. But there’s some great tools for documenting. I’ll talk about my favourite, Doxygen.
In the above section I said I’d go over what that weird stuff like \tparam was. Well, those are for Doxygen. Those are commands that Doxygen will interpret and use to structure the outputted help documentation. Oh, btw, that’s what it does. It generates HTML files, or help files (.chm), that documents your code.
You can also connect it to things like Graphviz so that it generates caller graphs and inheritance graphs.
Some commands can also create whole pages that are separate to the documentation of the code. This is how I create my Game Design Documents, everything is files in the project solution. Here’s an image of the documentation created for some of my own code:
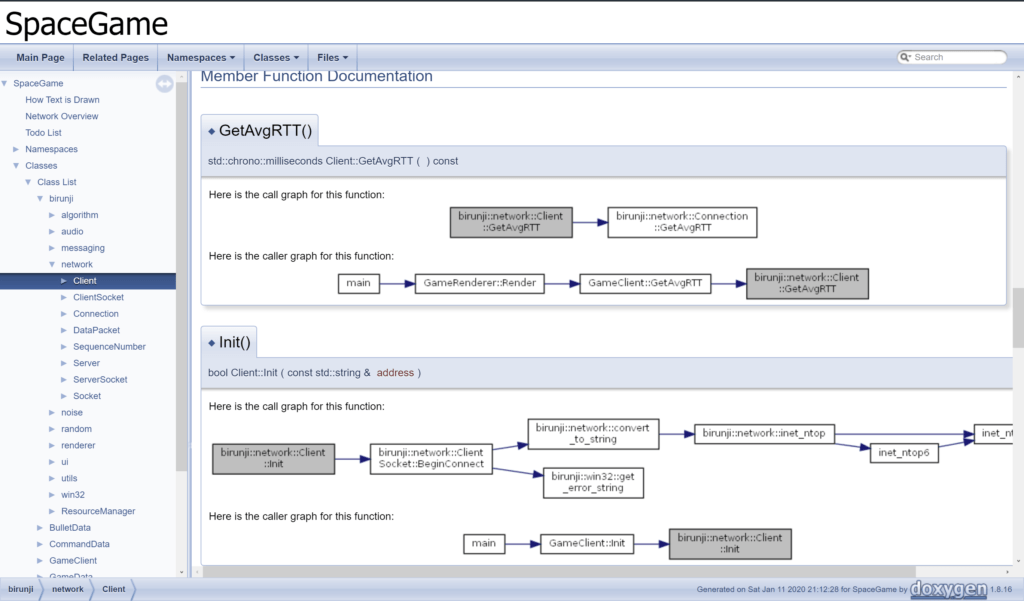
Doxygen itself is used for its own manual. SFML uses it for its online documentation as well.
For what its worth MkDocs is another solution for project documentation, but I havent got much experience with it.
I hope this helps some hobby game developers keep their code maintained and readable for years to come. Let me know if youve got experience with other methods of code documentation.